DataPool Overview
What is DataPool? Developed by the MIT Office of Sustainability, DataPool brings together key operational datasets such as building energy use, greenhouse gas emissions, water consumption, and transportation metrics, along with other campus sustainability data. It is a single, trusted platform that supports learning, collaboration, and informed action across the Institute.
Mission: To advance MIT’s climate and sustainability goals by making high-quality data accessible, actionable, and integrated into campus decision-making.
Who it serves: DataPool is a shared resource for MIT faculty, students, researchers, and operations teams working to understand and improve campus systems.
Driving Sustainability with Data
Effective sustainability work relies on clear, timely, and reliable data. Without it, we struggle to benchmark progress or identify where to act. In practice, many teams face delays in data updates, siloed systems, and inconsistent reporting.
DataPool addresses these challenges by centralizing disparate datasets into a single source of truth, backed by documentation, automated quality checks, and role-based access. The result is a system that transforms raw numbers into trusted insights, empowering the MIT community to drive meaningful action.
Who Uses DataPool
Faculty & Researchers: Researchers use DataPool to study energy systems, emissions, and climate resilience. Building on the Energize_MIT platform launched in 2017, faculty like Professor Christoph Reinhart have used it to test building energy models and assess carbon reduction strategies. New initiatives, such as the AI for Campus Operations pilot, apply machine learning to optimize building performance.
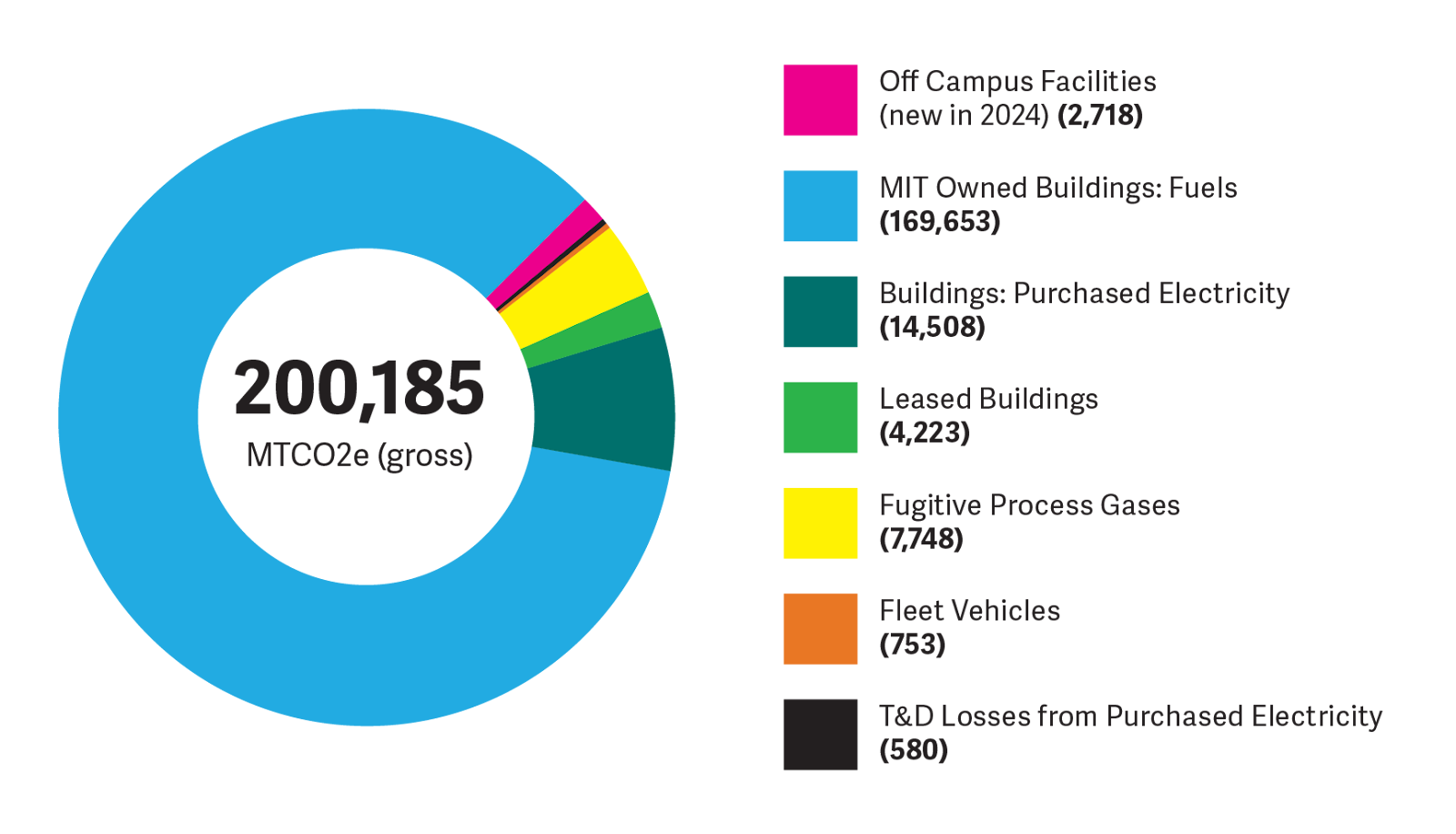
Operations Teams: Facilities and the Office of Sustainability rely on DataPool for system performance tracking, planning, and reporting. It underpins MIT’s annual greenhouse gas accounting, supports STARS certification, and helps identify energy savings and climate risks.
Students & Student Groups: Students use DataPool for applied research and analysis that can inform real-world initiatives. For example, the Sloan Sustainability Summit team used emissions data to estimate and offset the carbon footprint of their annual conference.
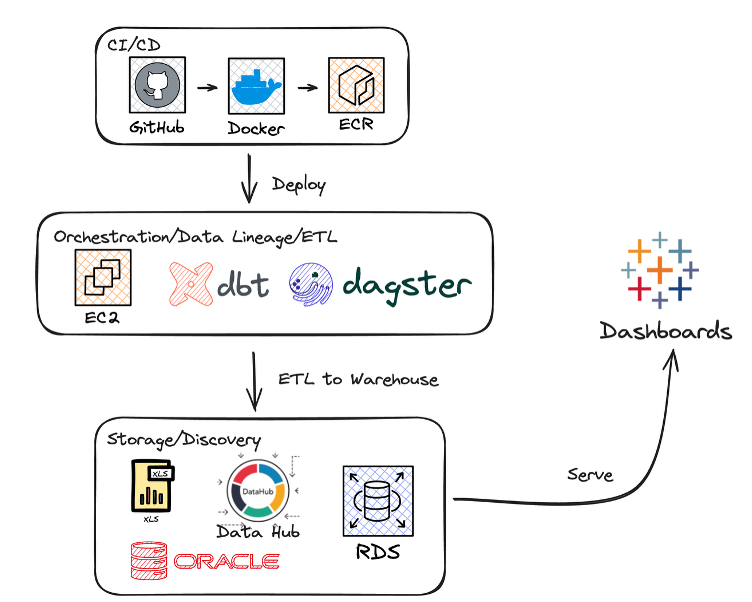
Behind the Scenes: Basin Data Platform
DataPool runs on the Basin Data Platform, built on AWS and MIT IS&T’s DataHub. It features a cloud-hosted data warehouse, automated workflows, built-in documentation, and data quality checks.
- Centralized Storage: Sustainability data is stored in a single Postgres database for consistency and fast access.
- Automation & Orchestration: Dagster schedules and monitors workflows; dbt manages version-controlled transformations.
- CI/CD Pipeline: GitHub Actions automates testing and deployment, ensuring all changes are reviewed and reproducible.
- Collaboration: MITOS works closely with departments, research labs, and peer institutions to share best practices and accelerate sustainability efforts.
Looking Ahead
We’re expanding DataPool with a scope 3 emissions dashboard covering purchased goods, business travel, capital goods (construction), and waste. A REST API is in development so departments can directly pull their GHG footprint data.
Your feedback shapes our evolution.
Email DataPool@mit.edu or open an issue on our GitHub repo to suggest new datasets, flag issues, or collaborate.